

Background
드디어 회사에서 개발하고 있는 서비스가 성능 검증을 받아야 하는 시기가 도래했습니다.
이전에는 기능에 대한 테스팅만을 진행하다 처음 성능 테스트를 하는 것입니다.
그렇기 때문에 개발 쪽에서 자체적으로 성능 수치를 제안해야 할 뿐 아니라,
성능에 대한 데이터 확보가 중요하게 되었습니다.
성능 측정을 처음 해보는 것이었기 때문에 어떤 성능 툴을 쓸까에 대한 내부적인 고민이 있었습니다.
후보는 jemter와 locust가 있었습니다.
그리고 저의 강력한 주장 때문에 locust가 테스팅 툴로 선정되었습니다.
Jmeter? Locust?
제가 성능 테스트가 처음임에도 불구하고 locust를 선택한 이유는, 두가지 때문이었습니다.
- 코드로 TC를 관리할 수 있다.
- jmeter에 비해 더 많은 user thread를 생성할 수 있다.
1. 코드로 TC 관리 가능
Jmeter도 코드로 TC를 관리할 수 있습니다. 하지만 xml 형식으로 되어 있어 xml에 능숙하지 않은 사람(본인)은 접근하기 쉽지 않았습니다. 그리고 jmeter 자체에서 코드로 짜는 방법을 권장하지 않습니다. 하지만 locust는 python으로 TC를 짤 수 있습니다. 아주 편리하고 재사용이 용이합니다. (그냥 기능 테스트를 할 때도 사용할 수 있습니다.)
저는 다음과 같은 구조로 test_runner는 shell script로 짜고, api 디렉토리에는 실제로 api를 call 하는 부분을 넣었습니다. tc 디렉토리는 하나하나의 endpoint에 대한 부하 테스트를 하기 위한 디렉토리입니다. user_scenario 디렉토리는 api에 존재하는 API들을 짜 맞춰 유저 시나리오를 테스트하는 suite을 만들어둔 디렉토리입니다.
/
├ test_runner.sh
├ token_generator.py
├ tc
│ ├ locust_tc1.py // calls api from api1.py
│ └ locust_tc2.py // calls api from api2.py
├ user_scenario
│ └ scenario.py // calls api1 -> api2 from api1.py, api2,py
└ api
├ api1.py
└ api2.py
2. Use Less Resources
이건 직접 해본 것이 아니라 조사 중 발견한 내용입니다.
Jmeter는 java based의 툴이고 user thread가 말 그대로 thread로 구현되어 있기 때문에 다소 무거운 반면, locust는 gevent 기반으로 user를 생성하기 때문에 jmeter 보다 가볍다는 글을 읽었습니다.
처음 locust를 구성할 때는 회사의 PC에서 가볍게 테스트를 치는 것이 필요했습니다.
회사는 proxy를 타고 있기 때문에 외부로 나가는 네트워크가 아주 느렸고, 조금이라도 user를 더 만들어서 테스트를 쳐보고 싶었기 때문에 locust를 선택하게 되었습니다.
Jmeter와 Locust를 비교하는 아주 좋은 아티클은 아래 링크에서 확인하세요.
https://www.blazemeter.com/blog/jmeter-vs-locust-which-one-should-you-choose/
Tips for Using Locust
이제 직접 다량의 삽질을 하며 얻은 노하우들을 공유해볼까 합니다.
자료 해석에 대한 내용들이 포함되어 있습니다.
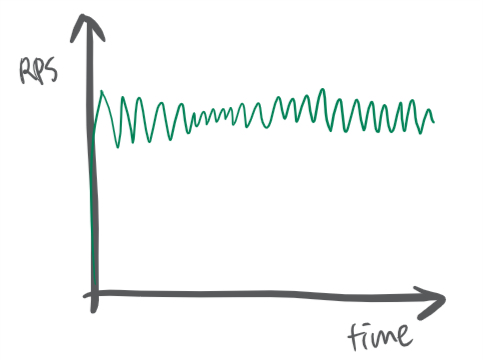
1. RPS is quite consistent
서비스 스케일에 변화가 없다면, RPS는 테스트 내내 일정합니다. 저는 처음에 테스트 시간이 지날 수록 RPS가 늘어날 것이라고 생각했습니다만 이건 경기도 오산이었습니다. 어짜피 서비스가 1초에 처리할 수 있는 request의 수는 정해저 있습니다. 테스트를 오래 친다고 늘어나지 않습니다. 만약 테스트 중에 RPS가 올라가는 경우라면 다음 항목들을 의심해볼 수 있을 것 같습니다. * kubernetes based의 서비스이고, 테스트 도중 pod이 늘어났다. * DDB를 사용하고 있고, 테스트 도중 partition이 늘어났다. * 서비스가 죽어서 갑자기 fail response가 겁나 빠르게 들어온다. 다른 요소들이 있을 수 있겠다만, 저는 위 두가지 이유가 아니라면, 다음과 같은 그래프처럼 테스트 내내 꽤나 일정한 RPS가 나왔습니다.
2. Test boundary
만약 test client가 충분한 양의 request를 만들어내지 못한다면, RPS가 원하는 만큼 나오지 않을 수 있다. 예를 들어 우리 서비스가 초당 10,000회의 request를 처리할 수 있다고 합시다. 각각의 request의 응답 시간은 500ms이구요. 그런데 우리의 test client의 성능은 동시에 최대 100회의 req만 만들어낼 수 있습니다. test client가 응답을 받고 다시 재빨리 요청을 보내면, 결국 test client는 초당 200번의 request을 보낼 수 있겠죠?? (응답 시간이 0.5초 니까요) 결국 우리 서비스는 초당 10,000 이라는 좋은 수치를 가지고 있지만, 결국 RPS는 200으로 측정될 것입니다. 그래서 서비스가 fail을 내는 그 경계선을 찾는 것이 의미가 있을 수 있습니다. 서비스가 견딜 수 있는 최대한의 request를 찾아서 성능 개선의 효과를 데이터로 입증할 수 있을 것입니다. 물론 이건 scale out되지 않는 서비스에 한정된 내용입니다.
3. Master-slave 구조의 필요성
2번의 연장으로, test client한테 user thread를 많이 생성하도록 설정한다고 해서 test client device가 그만큼의 request를 내보낼 수 있는 것은 아닙니다. 이것이 바로 master-slave구조가 필요한 이유입니다. 경험적으로 2,000개의 user thread를 만들 때 slave를 20대 생성하고, 하나의 slave당 100개의 user thread를 생성하도록 하여 테스트하고 있습니다. (jmeter에서도 이 정도 user thread를 생성가능한 것으로 알고 있습니다.) 개인적으로 하나의 test client에서 더 많은 request를 내보낼 수 있도록 튜닝하는 방법이 있는지 알아보고 있는 중입니다.
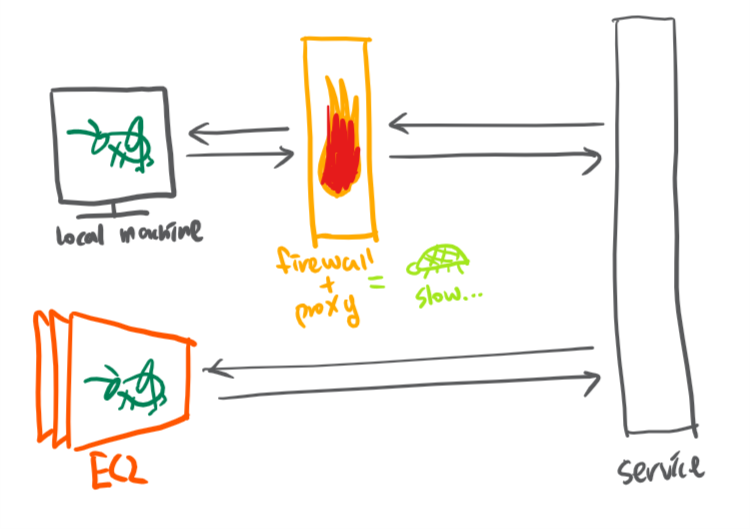
4. test client 위치
test client의 위치도 test 결과에 영향을 많이 미칩니다. 특히 회사 안에서 proxy를 사용하는 경우라면 더더욱. 제가 다니는 회사는 프록시를 사용하고 , 서비스 자체는 EKS에 올라가 있습니다. 회사의 local machine에서 health check 테스트를 돌렸을때는 200ms가 넘었고, EC2에서 동일한 health check를 했을 때는 한 자리에 수렴하는 결과가 나왔습니다. 아마 외부 네트워크를 쓰는 이유도 있겠지만, EC2 ←→ EC2여서 더 응답 시간이 짧은 것 같습니다.
5. Get Hints From Fail
일단 fail이 일어나고 난 후의 결과는 더 이상 믿을 수 있는 값이 아닐 수 있습니다. 그렇지만 힌트를 얻을 수 있습니다. 만약 service가 죽어버려서 바로 error code를 리턴해주는 경우라면, 빠른 속도로 error를 리턴해 줄 것입니다. 이 경우에 시간이 길어지고 서비스 복구가 이루어지지 않으면 결국 fail rate은 올라가고 response time은 낮아질 것입니다. fail rate이 높다면 응답 시간 역시 믿을 것이 못됩니다. 이런 경우에는 서비스로 향하는 부하를 더 적게 해서 테스트해보는 것이 좋습니다. 만약 fail 이 발생하자마자 max time의 시간이 늘어난다면 서비스에서 timeout시간을 초과했기 때문일 수 있습니다. 이 경우에는 timeout을 핸들링하는 로직을 추가하는 것을 고려해볼 수 있습니다. (가령 timeout시간을 줄이고, retry 로직을 넣는다던지 ⇒ 실제로 동료가 문제를 이렇게 해결한 후 max time이 대폭 줄어든 것을 확인한 적이 있습니다.)
Conclusion
locust는 가볍고 쉽게 테스트를 돌릴 수 있는 툴이지만, Jmeter만큼 완성도가 높은 툴인 것 같지는 않습니다. 돌리면서 눈에 띄는 몇몇 버그를 발견하였습니다. (fail rate 계산법이 이상하다던가, slave에서 error갯수를 제대로 표시해주지 못한다거나)
그렇지만 code로 TC를 관리할 수 있는 등 여러 장점이 분명히 존재하는 툴이니, 각자의 성향이나 상황에 맞게 사용하시면 좋을 것 같습니다.



