
- Today
- Total
코기판
EKS에 클러스터 오토스케일링(cluster autoscaling) 하기 본문
지난 번 포스팅에서 이야기 했듯이,
EKS의 각각의 worker node는 EC2 instance인데,
아무리 작은 크기의 pod이라고 해도, 무한정 pod을 배포시킬 수는 없다.
그래서 여러 명의 개발자가 pod을 많이 배포시키거나,
HPA(Horizontal Pod Autoscaling)에 의해 여러 개의 pod이 만들어지면,
node가 가득 차버려서, pod이 스케줄 될 수 없어 pending 상태에 머무르는 상황이 발생한다
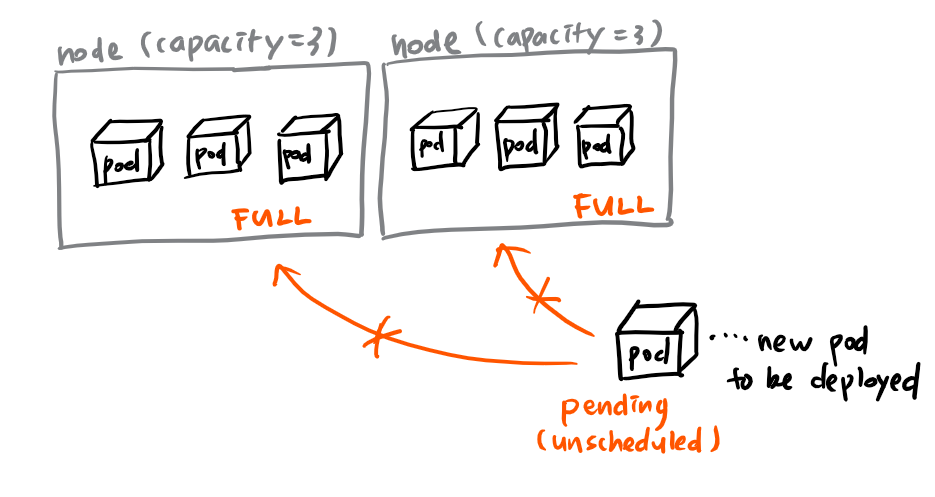
이럴 때 필요한 것이 바로 Clustster autoscaling(CA)이다
처음 cluster autoscaling이라는 단어를 들었을때,
"클러스터 자체를 여러개 늘리는건가..?" 라는 생각을 했다.
하지만, CA는 worker node의 갯수를 늘리는 것이다.
pod이 여러개로 늘어가는거는 pod autoscaling이면서 !!
왜 node가 여러개로 늘어나는 것은 node autoscaling이라고 하지 않고 cluster autoscaling이라 하는지 잘 모르겠다
아무튼 새로운 node를 만드는 것은 node autoscaling(X), cluster autoscaling(O)이다.
처음에는 AWS 서비스 중 하나인, cloud watch를 이용해서 늘려야 하나.. 싶었는데
가이드 되어있는 가장 일반적인 방법은 kubernetes(k8s)의 cluster autoscaler 모듈을 사용하는 것이다.
처음에는 k8s가 EC2를 어쩌지 못할텐데.. 라는 의심이 들었다
결론부터 말하자면, k8s는 EC2를 직접 만드는 것에는 관여할 수 없고,
약간의 꼼수처럼 AWS의 Autoscaling group의 desired capacity 갯수를 바꾸어준다
즉, CA를 적용하게 되면,
1. 시작할 자리가 없어서 pending 되어있는 pod이 있는지 살펴본다 (Unscheduled pod)
2. CA가 desired capacity의 갯수를 바꾼다
3. AWS가 새로운 EC2인스턴스를 만들고, 이것이 새로운 worker node가 된다.
(이 때 시간이 많이 소요된다)
4. pod들이 새로운 worker node에 스케줄링 된다.
즉, 다음과 같은 일이 생기는 것

일단 해당 플로우가 가능하게 하려면, AWS리소스 요청을 보내기 위해 IAM 정책 설정을 해야한다
|
mkdir ~/environment/asg_policy cat <<EoF > ~/environment/asg_policy/k8s-asg-policy.json { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "autoscaling:DescribeAutoScalingGroups", "autoscaling:DescribeAutoScalingInstances", "autoscaling:SetDesiredCapacity", "autoscaling:TerminateInstanceInAutoScalingGroup" ], "Resource": "*" } ] } EoF aws iam put-role-policy --role-name $ROLE_NAME --policy-name ASG-Policy-For-Worker --policy-document file://~/environment/asg_policy/k8s-asg-policy.json
|
policy를 찬찬히 뜯어보면, 저 정책이 desired capacity를 바꾸어 준다는 사실을 대충 알 수 있다
그 다음으로 할 일은,
명시적으로 min값과 max값 그리고 asg name을 지정할 수도 있지만,
k8s에서는 auto discovery라는 아주 편리한 기능을 제공한다.
auto discovery 예제는 k8s에서 친절하게 github에 올려두었다 (여기를 클릭)
여기서 중요한 부분은 command부분이다. 특히 굵은 글씨.
|
command: - ./cluster-autoscaler - --v=4 - --stderrthreshold=info - --cloud-provider=aws - --skip-nodes-with-local-storage=false - --expander=least-waste - >- --node-group-auto-discovery=asg:tag=k8s.io/cluster-autoscaler/enabled, k8s.io/cluster-autoscaler/<YOUR CLUSTER NAME> |
저 굵은 글씨의 k8s.io/cluster-autoscaler/enabled 와 k8s.io/cluster-autoscaler/<YOUR CLUSTER NAME> 는
Autoscaling group의 태그에 해당한다
즉, aws가 저 값을 보고 어떤 asg를 스케일링 할 것인지 판단하기 때문에 저 값을 잘 넣어주어야 한다
태그 이름은 회사에서 내가 설정한 값이 아니기 때문에 사실 나도 잘 모르겠는데,
나의 경우
{ k8s.io/cluster-autoscaler/enabled : true }
{ kubernetes.io/cluser/{my-cluster-name} : owned }
로 되어있었던 것 같다
asg의 태그 이름은 여기서 확인할 수 있다

.yaml 파일을 kubectl 명령어로 바로 apply하거나,
terraform을 쓰고 있다면 deployment 할 때 해당 yaml을 포함하여 deploy하기만 하면,
꽤나 쉽게 CA를 적용할 수 있다
불편한 점은 몇가지 있었는데,
1. AWS에서 instance를 프로비저닝 하는 시간이 꽤 느리다 체감 상 2,3 분에서 5분까지도 걸린다
만약 pod에 사용량이 몰려서 hpa가 일어나는 중이라면, instance provisioning 시간 때문에 error response가 생길 수 있다.
2. Scale in(사용하지 않는 노드가 줄어드는 것, 다른 말로 scale down)역시 너무너무 느리다..
기본 10분이었던가 사용하지 않아야 그제서야 pod scheduler에서 정말 필요없는 node인지를 검사한다 ..
이 부분은 조절하는 옵션이 있어서 3m정도로 주고 테스트했다
이 모든 일이 회사에서 일어났기 때문에 코드와 스크린샷은 https://eksworkshop.com/scaling/deploy_ca/ <- 요기에서 가져왔다
그리고 실제로 해봤는데, 위 링크의 예제는 아주 잘 동작한다 !!
여담이지만, 오늘 새로운 노트북이 와서 열심히 그림도 그려보았다 !!
pen S 진짜 좋다 !!
앞으로 이걸로 다이어그램도 많이 그리고 더 열심히 공부해야겠다
일단 티스토리에 소스코드 예쁘게 넣는 방법부터 익혀야지 ..
'Infra' 카테고리의 다른 글
| grpc client load balancing 구현하기 (grpc 번외편) (0) | 2019.05.28 |
|---|---|
| protobuf란 무엇인가? (gRPC 시리즈 #2) (1) | 2019.05.12 |
| gRPC란 무엇인가? (gRPC 시리즈 #1) (5) | 2019.04.21 |
| k8s pod autoscaler 개념 (HPA, VPA) (0) | 2019.04.02 |
| AWS EKS 배포 가능한 최대 pods 갯수 (0) | 2019.03.09 |


